시각화의 옵션 Facets
면분할이라고도 한다. Facets을 활용하면 다양한 그래프를 한 화면에 담을 수 있는 장점이 있다.
facets() 함수와 관련해서 크게 4가지 기준으로 작성한다.
- facets 기본예제
- Customizing Layout
- Re-Arrange
- 라벨링
- Y축 스케일 적용
- facets()를 활용한 그룹화
데이터셋
이번 데이터는 GDP관련 데이터를 활용하려고 한다. gapminder 데이터셋을 활용하려고 한다.
# install.packages("gapminder")
library(gapminder)
dplyr::glimpse(gapminder)## Observations: 1,704
## Variables: 6
## $ country <fct> Afghanistan, Afghanistan, Afghanistan, Afghanistan, Af…
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, …
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 148803…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.…gapminder 데이터는 스웨덴의 비영리 통계분석 서비스의 일종이며, 유엔의 데이터를 바탕으로 한 인구 예측, 부의 이동 등과 같은 연구논문을 게재하고 있다. RStudio 회사에서 직접 데이터셋을 정리하여 업데이트를 하고 있다.
각 변수에 대한 자세한 설명은 RStudio Editor에서 ?gapminder를 실행해보자.
사전 준비작업
- 연도는 2007년도 기준으로 구분하려고 한다. dplyr 패키지 안에 포함된 filter() 함수를 활용했다.
- select() 함수를 활용 하여 각 대륙별 대표국가만 추출하여 그래프를 작성하도록 한다.
- Australia
- Brazil
- Korea, Rep.
- Nigeria
- Germany
- United States
library(dplyr)
gapminder2 <- gapminder %>%
filter(year == 2007, country %in% c("Australia", "Brazil", "Korea, Rep.", "Nigeria", "Germany", "United States"))기본 그래프
첫번째 막대그래프, X축은 country 활용할 것이고, Y축은 lifeExp를 활용할 것이다.
ggplot(gapminder2, aes(x = country, y = lifeExp)) +
geom_bar(stat = 'identity', fill = 'forest green')
두번째 막대그래프, X축은 country 활용할 것이고, Y축은 gdpPercap을 활용할 것이다.
ggplot(gapminder2, aes(x = country, y = gdpPercap)) +
geom_bar(stat = 'identity', fill = 'forest green')
여기서 한가지 불편함을 느껴야 한다. X축은 동일한 변수 continent를 사용했지만, Y축은 lifeExp과 pop을 나눠서 그래프를 그렸다. 합칠 수 있는 방법이 없을까?
우선 간단한 Tip을 드리자면 Y축 두개 변수에 담고 있는 데이터를 합칠 필요가 있다.
gather() 함수를 사용해서 가공한다.
gather()
gather() 함수는 tidyr 패키지안에 내장 되어 있는 함수다. tidyr 패키지 사용 예제는 데이터 가공 때 다시 한번 다루도록 한다.
library(dplyr)
library(tidyr)
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))기존 gapminder 데이터와 다르게 lifeExp와 pop 데이터가 합쳐진 것을 볼 수가 있다. 이 상황에서 facet_wrap() 함수를 적용하여 시각화를 진행하면 아래와 같다.
facets 기본예제
ggplot(gapminder3, aes(x = country, y = value)) +
geom_bar(stat = 'identity', fill = 'forest green') +
facet_wrap(~records)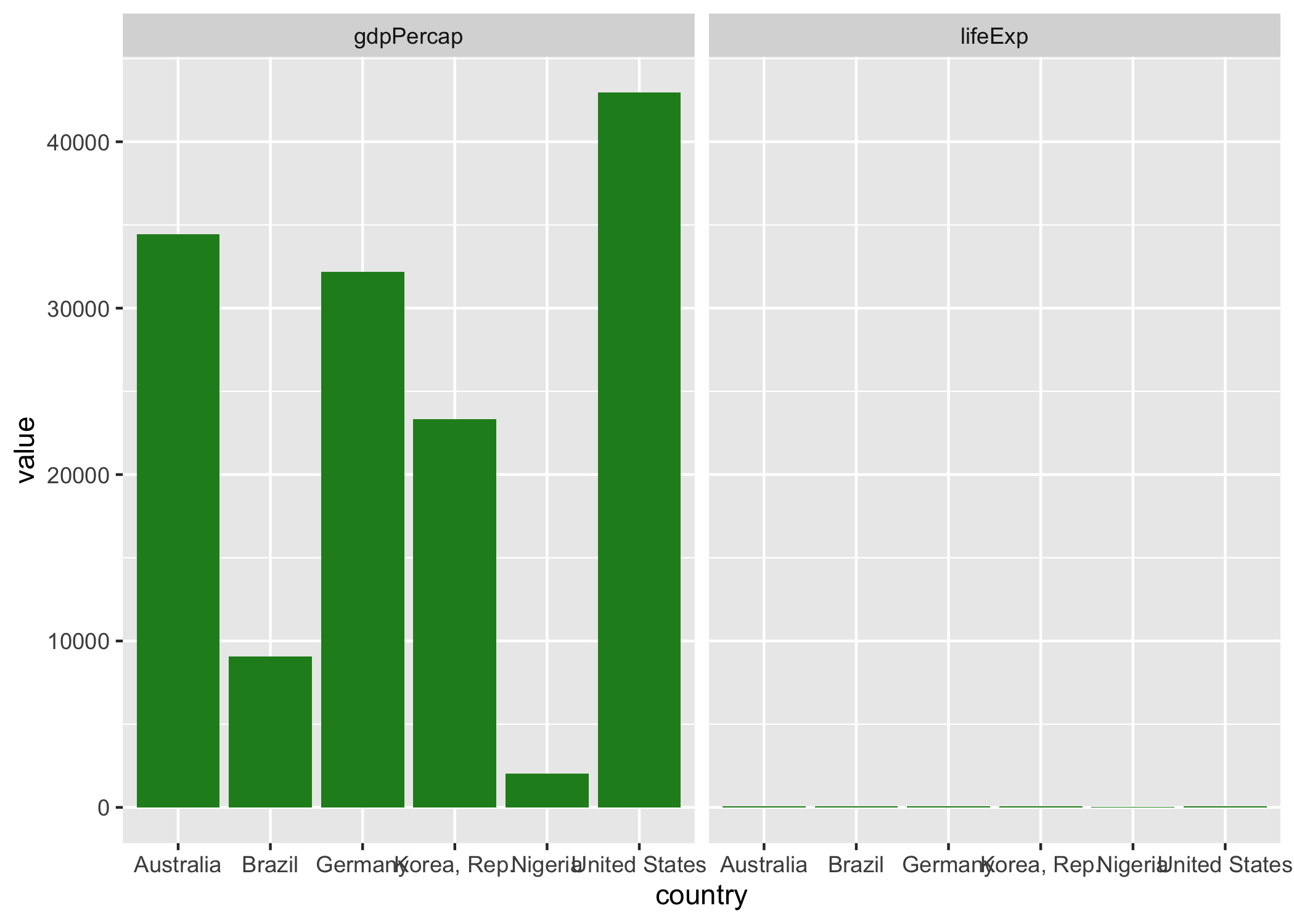
위 그래프의 문제점은 무엇일까?
- X축의 글자가 겹쳐보인다는 점
- 나라의 알파벳 순서대로 배여 되었다는 점
- Y축 Value가 다르기 때문에 그래프를 합치면 해석이 난해해진다는 점이다.
이러한 문제를 어떻게 해결하면 좋을지 하나씩 해결해보자.
Customizing Layout
facet_wrap() 함수에 인자값 ncol = 1을 입력해보자.
ggplot(gapminder3, aes(x = country, y = value)) +
geom_bar(stat = 'identity', fill = 'forest green') +
facet_wrap(~records, ncol = 1)
X축의 나라이름이 겹쳐보인 것은 해결을 하였다.
Re-Arrange
gdpPercap 기준으로 이제 정렬을 해보자. 이 때 factor() 함수를 사용한다.
gapminder2$country <- factor(gapminder2$country,
levels = gapminder2$country[order(gapminder2$gdpPercap)])
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))
ggplot(gapminder3, aes(x = country, y = value)) +
geom_bar(stat = 'identity', fill = 'forest green') +
facet_wrap(~records, ncol = 1)
변수 gdpPercap & lifeExp 이름이 가독성이 좋지 않아서 Y축으로 옮기고 싶다면, 기존 facet_wrap() 안에 strip.position = "left" 코드를 추가적으로 입력한다. 아래와 같이 코드를 실행해본다.
gapminder2$country <- factor(gapminder2$country,
levels = gapminder2$country[order(gapminder2$gdpPercap)])
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))
ggplot(gapminder3, aes(x = country, y = value)) +
geom_bar(stat = 'identity', fill = 'forest green') +
facet_wrap(~records, ncol = 1, strip.position = "left")
라벨링
gdpPercap과 lifeExp는 일종의 약어이다. 독자들에게 Full Name을 보여주는 것은 시각화의 기본적인 의무이기도 하다. facet_wrap() 함수안에 labeller=를 활용해본다.
gapminder2$country <- factor(gapminder2$country,
levels = gapminder2$country[order(gapminder2$gdpPercap)])
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))
var_names <- list(
"lifeExp" = "Life Expectancy" ,
"gdpPercap" = "GDP Per Capita"
)
var_labeller <- function(variable,value){
return(var_names[value])
}
ggplot(gapminder3, aes(x = country, y = value)) +
geom_bar(stat = 'identity', fill = 'forest green') +
facet_wrap(~records, ncol = 1, strip.position = "left", labeller = var_labeller)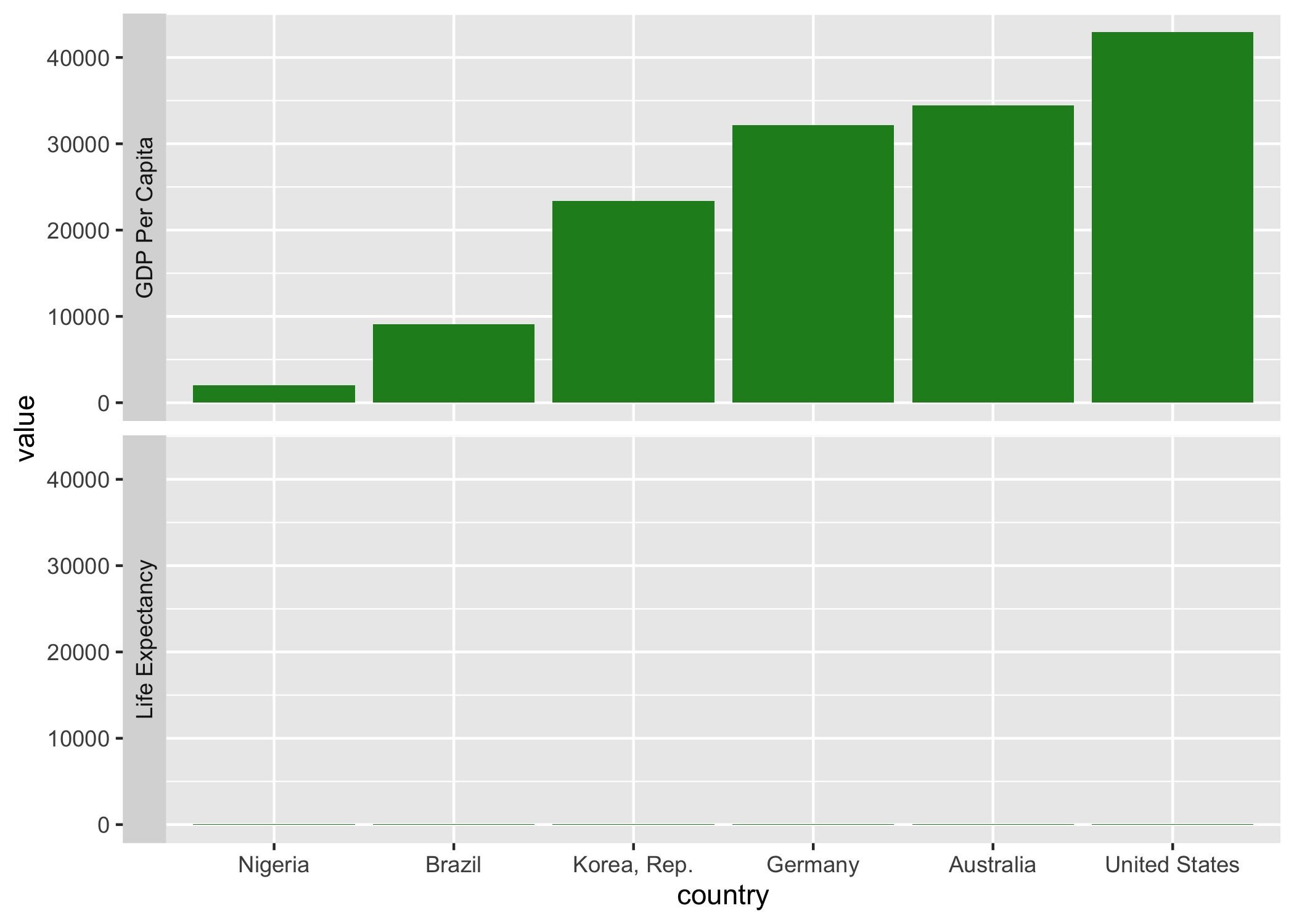
lifeExp가 Life Expectancy로 gdpPercap가 GDP Per Capita로 변경된 것을 확인할 수 있다.
Y축 스케일 적용
여전히 한가지 문제가 풀리지 않고 있다. gdpPercap 변수에 관한 그래프는 잘 나와 있는 반면 Life Expectancy에 관한 그래프는 확인이 되지 않는다. 또 하나 문제점 중의 하나는 Y축 Scale이 gdpPercap 기준으로 맞춰져 있다. 이를 해결하기 위해서는 기존 소스 코드, facets() 함수에 scales = "free_y"를 입력하도록 한다.
추가적으로 대륙별로 확인하기 위해 aes() 함수 안에 fill = continent를 추가한다. 대신, geom_bar() 함수 안에 있던 fill = 'forest green'는 제거한다.
gapminder2$country <- factor(gapminder2$country,
levels = gapminder2$country[order(gapminder2$gdpPercap)])
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))
var_names <- list(
"lifeExp" = "Life Expectancy" ,
"gdpPercap" = "GDP Per Capita"
)
var_labeller <- function(variable,value){
return(var_names[value])
}
ggplot(gapminder3, aes(x = country, y = value, fill = continent)) +
geom_bar(stat = 'identity') +
facet_wrap(~records, ncol = 1, strip.position = "left", labeller = var_labeller, scales = "free_y")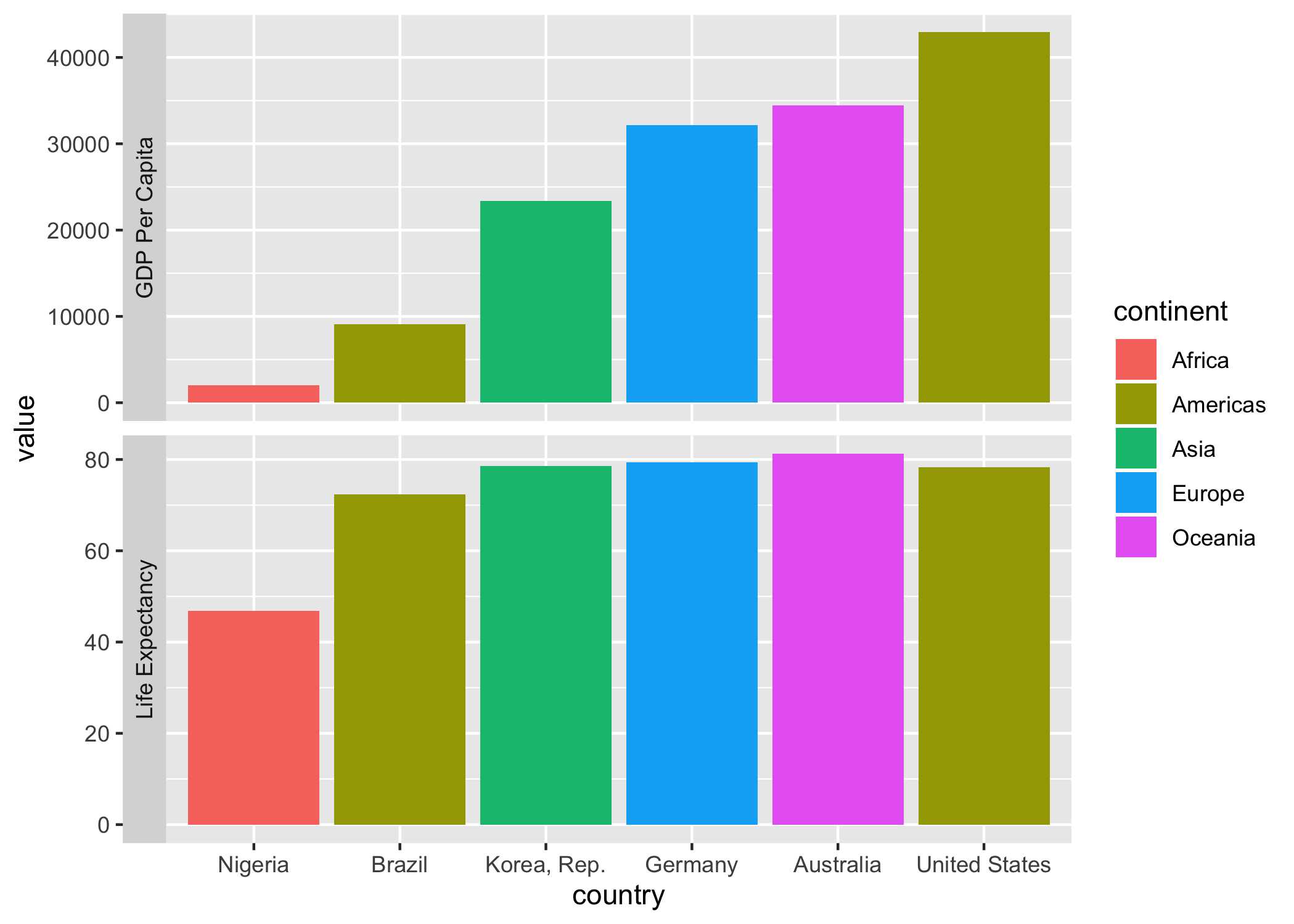
facets()를 활용한 그룹화
이제 마지막이다. 각 대륙별 나라를 한개씩 더 늘린 후, 대륙별로 그룹화를 하려고 한다. 또한 각 대륙별로 그룹화를 할 때, 공간으로 구분할 수 있도록 하려고 한다. 아래 전체 소스코드를 확인해본다.
그동안에는 facet_wrap() 함수를 사용했지만, 이번에는 facet_grid() 함수를 사용했다. 이렇게 변수 2개를 추가로 넣을 경우에는 facet_wrap() 함수보다는 facet_grid() 함수가 더 나을 수 있다.
library(dplyr)
gapminder2 <- gapminder %>%
filter(year == 2007, country %in% c("Australia", "Korea, Rep.", "Nigeria", "Germany", "United States", "Canada", "France", "South Africa", "Japan", "New Zealand"))
gapminder2$country <- factor(gapminder2$country,
levels = gapminder2$country[order(gapminder2$gdpPercap)])
gapminder3 <- gapminder2 %>%
gather(key = "records", value = "value", c("lifeExp", "gdpPercap"))
var_names <- list(
"lifeExp" = "Life Expectancy" ,
"gdpPercap" = "GDP Per Capita"
)
continent_names <- levels(gapminder3$continent)
var_labeller <- function(variable,value){
if (variable=='records') {
return(var_names[value])
} else {
return(continent_names)
}
}
ggplot(gapminder3, aes(x = country, y = value, fill = continent)) +
geom_bar(stat = 'identity') +
facet_grid(records~continent, labeller = var_labeller, scales = "free", space="free_x") +
theme(legend.position = "none", axis.text.x = element_text(angle = 15, vjust = 0.8))
facets() 함수를 사용할 때, 입문자는 드디어 R의 편리성과 탁월함에 대해 느끼게 될 것이다. 위 코드안에는 단순히 시각화 코드 뿐 아니라 tidyr & dplyr 패키지 안에 있는 함수들도 같이 사용되어졌다. 또한, factor()와 levels() 함수를 사용하여 각 변수의 values() 추출하는 것도 포함되어 있다.
지금은 걱정안하셔도 된다. 시각화가 끝나고 나면 dplyr & tidyr 패키지에서 한번 더 다룰 예정이다.
지금까지 진행한 소스코드를 다른 데이터를 적용하여 해보도록 해보자. 실제 실무데이터를 활용해보면 훨씬 더 빠르게 습득 할 수 있고, 이해하기도 쉬울 것이다.
나에게 위 게시글에 영감을 준 facets() 포스트: Facets for ggplot in R
'R > [R] 데이터 시각화' 카테고리의 다른 글
| [R Markdown] Adjusting figure options, optimizing them for mobile devices (From DataCamp) (0) | 2019.05.04 |
|---|

