This post is about "R interface for Apache Spark" using R package. For newbie like me, settings, installation, prerequisite, etc.. interfacing, connectings between components are always hard, most of cases, it takes lots of time.
Wanna share kindly with others the important notes when settings are ongoing.
Okay, Let's begin.
My Session Info() is below
> sessionInfo()
R version 3.6.0 (2019-04-26)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS 10.15.11. List of Downloads
Please read below carefully before downloading resources.
> Note: Spark runs on Java 8, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.4.4 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x) (Dec 2019).
Personally, I was in trouble with settings because of Java versions. The version of Java was Java 11. and it was difficult to use. If you don't have Java 8, then please download Java 8. (Spark Documentation)
Overview - Spark 2.4.4 Documentation
Spark Overview Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools
spark.apache.org
The other way to download them is via brew command.
$ brew install blah~But, In this post, the way will not be included. Okay, lists of downloads are followed.
- JAVA: [jdk-8u231]
Java SE Development Kit 8 - Downloads
Java SE Development Kit 8 Downloads Thank you for downloading this release of the Java™ Platform, Standard Edition Development Kit (JDK™). The JDK is a development environment for building applications, applets, and components using the Java programming la
www.oracle.com
- Scala: [scala-2.13.1]
- SBT: [sbt-1.3.4]
- Spark can be downloaded via R Package [sparklyr]
sparklyr
2018-10-02 — Announcement We are excited to share that sparklyr 0.9 is now available on CRAN! Spark Stream integration, Job Monitoring and support for Kubernetes Read More… 2018-04-09 — Announcement We are very excited to announce that the graphframes pack
spark.rstudio.com
You can install the sparklyr package from CRAN
install.packages("sparklyr")
Setting version is important, you may check which version is available with spark_available_versions().
library(sparklyr)
spark_available_versions()The, You are able to install a local version of Spark for development purposes:
> spark_install(version = "2.4.0")
Installing Spark 2.4.0 for Hadoop 2.7 or later.
Downloading from:
- 'https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz'
Installing to:
- '~/spark/spark-2.4.0-bin-hadoop2.7'
trying URL 'https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz'
Content type 'application/x-gzip' length 227893062 bytes (217.3 MB)When running spark_install(), the spark installation folders are downloaded at directory ~/spark/spark-2.4.0-bin-hadoop2.7
Then, you get all resources in order to connect between spark and R.
2. Preparations
2.1. Home folder
-
The main home folder is /Users/your_account_name
-
If you don't know your home folder, then please type cd $HOME and run it.
-
My case is /Users/evan/
2.2. The installation folder
-
Java, Python are sets automatically when installing it. You don't need to touch them.
-
However, Sbt, Scala, and Spark will be installed at /Users/evan/server
-
How to make server folder on terminal? It's easy.
~ evan$ mkdir server
~ evan$ cd serverNote for beginners, the command cd changes your working directory (from wherever it is) to HOME directory.
2.3 Move all downloaded files to $HOME/server folder
Once you copy all files, please double check the necessary files like below. scalar, sbt, spark

3. Set up Shell Environment editing bash_profile file
Here are the directory paths of the programs that we have installed so far:
-
JDK: /Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk
-
Python: /Library/Frameworks/Python.framework/Versions/3.7
-
Sbt: /Users/evan/server/sbt
-
Scala: /Users/evan/server/scala-2.13.1
-
Spark: /Users/evan/server/spark-2.4.0-bin-hadoop2.7
To check one more if every folder is at the directory where it should be, always use the command cd. For instance try to put command $ cd /Users/evan/server/sbt. If directory is changed, then it's correct. if not, then some files are not saved correctly.
3.1. Set up .bash_profile file
-
For beginners, this file starts with a “dot”. Therefore, make sure that you type the file name correctly, which is .bash_profile (with a “dot” in front).
-
Open the .bash_profile file, which is located at your HOME directory (i.e., ~/.bash_profile), using any text editor (e.g., TextEdit, nano, vi, or emacs). For example, my favorite editor is emacs. So, it could be following.

3.2. Edit .bash_profile file
Copy these lines to the file.
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home/
export SPARK_HOME=/Users/evan/server/spark-2.4.0-bin-hadoop2.7
export SBT_HOME=/Users/evan/server/sbt
export SCALA_HOME=/Users/evan/server/scala-2.13.1
export PATH=$JAVA_HOME/bin:$SBT_HOME/bin:$SBT_HOME/lib:$SCALA_HOME/bin:$SCALA_HOME/lib:$PATH
export PATH=$JAVA_HOME/bin:$SPARK_HOME:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export PYSPARK_PYTHON=python3When copyting to .bash_profile, DO NOT DELETE OTHER LINES. After copying all to .bash_profile, then save and close file.
3.3. Apply update .bash_profile file
Since the .bash_profile has been changed, we have to reload it. Options are
- back to terminal, and type
source ~/.bash_profile-
Quit and reopen the Terminal program. Make sure you completely quit the Terminal using menu → Quit Terminal (⌘Q), otherwise the environment variables declared above will not be loaded.
4. Connecting to Spark
You can connect to both local instances of Spark as well as remote Spark clusters. Here we’ll connect to a local instance of Spark via the spark_connect function:
> library(sparklyr)
> sc <- spark_connect(master = "local", spark_home = "your_spark_home_dir/spark-2.4.0-bin-hadoop2.7/")
* Using Spark: 2.4.0Welcome to Spark. The details are sparklyr: R interface for Apache Spark
sparklyr
2018-10-02 — Announcement We are excited to share that sparklyr 0.9 is now available on CRAN! Spark Stream integration, Job Monitoring and support for Kubernetes Read More… 2018-04-09 — Announcement We are very excited to announce that the graphframes pack
spark.rstudio.com
5. Examples
All sample codes are written at the offical documentations.
5.1. Using dplyr
We are able to use all of the available dplyr functions within the spark cluster.
We’ll start by copying some datasets from R into the Spark cluster (note that you may need to install the nycflights13 and Lahman packages in order to execute this code):
> library(dplyr)
> library(nycflights13)
> library(Lahman)
> iris_tbl <- copy_to(sc, iris)
> flights_tbl <- copy_to(sc, nycflights13::flights, "flights")
> batting_tbl <- copy_to(sc, Lahman::Batting, "batting")
> src_tbls(sc)
[1] "batting" "flights" "iris"
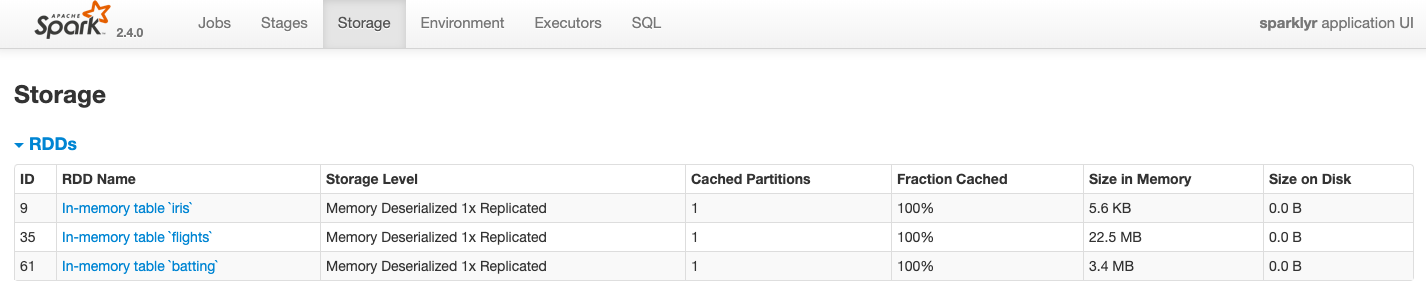
When copyting to spark, you may see these dataset at spark UI. Open web browser, type http://localhost:4040/storage/. Then you may see pic below.
Let's use filter() in dplyr package
# filter by departure delay and print the first few records
> flights_tbl %>% filter(dep_delay == 2)
# Source: spark<?> [?? x 19]
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 542 540 2 923 850
3 2013 1 1 702 700 2 1058 1014
4 2013 1 1 715 713 2 911 850
5 2013 1 1 752 750 2 1025 1029
6 2013 1 1 917 915 2 1206 1211
7 2013 1 1 932 930 2 1219 1225
8 2013 1 1 1028 1026 2 1350 1339
9 2013 1 1 1042 1040 2 1325 1326
10 2013 1 1 1231 1229 2 1523 1529
# … with more rows, and 11 more variables: arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Here, you may read # Source: spark<?> [?? x 19]. This points that dplyr function uses datasets from spark-cluster stored.
5.2. Using SQL
It's possible to execute SQL queries directly against tables if you are more familar with SQL. The spark_connection object implements a DBI interface for Spark, so you can use dbGetQuery to execute SQL and return the result as an R data frame:
> library(DBI)
> iris_preview <- dbGetQuery(sc, "SELECT * FROM iris LIMIT 10")
> iris_preview
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
5.3. Machine Learning
You can orchestrate machine learning algorithms in a Spark cluster via the machine learning functions within sparklyr. These functions connect to a set of high-level APIs built on top of DataFrames that help you create and tune machine learning workflows.
Here’s an example where we use ml_linear_regression to fit a linear regression model. We’ll use the built-in mtcars dataset, and see if we can predict a car’s fuel consumption (mpg) based on its weight (wt), and the number of cylinders the engine contains (cyl). We’ll assume in each case that the relationship between mpg and each of our features is linear.
# copy mtcars into spark
> mtcars_tbl <- copy_to(sc, mtcars)
# transform our data set, and then partition into 'training', 'test'
> partitions <- mtcars_tbl %>%
+ filter(hp >= 100) %>%
+ mutate(cyl8 = cyl == 8) %>%
+ sdf_random_split(training = 0.5, test = 0.5, seed = 1099)
# fit a linear model to the training dataset
> fit <- partitions$training %>%
+ ml_linear_regression(response = "mpg", features = c("wt", "cyl"))
> fit
Formula: mpg ~ wt + cyl
Coefficients:
(Intercept) wt cyl
33.499452 -2.818463 -0.923187
> summary(fit)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.752 -1.134 -0.499 1.296 2.282
Coefficients:
(Intercept) wt cyl
33.499452 -2.818463 -0.923187
R-Squared: 0.8274
Root Mean Squared Error: 1.422Spark machine learning supports a wide array of algorithms and feature transformations and as illustrated above it’s easy to chain these functions together with dplyr pipelines.
6. Conclusion
Dealing with this tutorial for a couple of days. The hard thing to me was to satisfy system requirements. Environment settings are not always comfortable with me who has studied Liberal Arts - Philiosophy, Religious Studies, Development Studies. All area is trying to collect data and store somewhere else, and get data from Database or Clusters, and finally analyse them. Although settings up data pipeline is a bit far away from analyzing data, still it's valuable for them to deal with part of data engineering area.
Hope to enjoy and happy to code.
References: https://medium.com/luckspark/installing-spark-2-3-0-on-macos-high-sierra-276a127b8b85
Installing Apache Spark 2.3.0 on macOS High Sierra
Apache Spark 2.3.0 has been released on Feb 28, 2018. This tutorial guides you through essential installation steps on macOS High Sierra.
medium.com
'R > [R] DB Connection' 카테고리의 다른 글
| [R] DB Connection with MySQL (0) | 2018.12.11 |
|---|